
Having just spoken at the great AI conference in New York, here are some observations:
First about AI
Most quants prefer the term Machine Learning (ML) instead of AI.
Questions still remain of where AI (ML) adds value in a quant investment process.
For example, Man’s CIO Sandy Rattray said that it works well for the execution of trades but is not that helpful in forecasting returns (see here). He talked about the many ‘rabbit holes’ of ML - research directions that don’t produce any value - such as Satellite Imaginary analysis. ML in Risk Models and attribution is very difficult to explain to clients as factors have little economic interpretability.
WorldQuant’s CTO David Rushin talked about how these advanced machine learning approaches can remove the bottlenecks of in-taking, preparing, cleaning and testing the new datasets, shortening the research cycle.
AQR’s Marcos Lopez de Padro talked about the successes of ML in risk management and probability estimation. He talked about the necessity of ML for large data processing and analysis, yet he did not directly discuss ML’s return forecasting success.
Several start-up hedge funds talked about using ML in Multi-Asset / Macro type of forecasting using a large number of macro-economic time-series to estimate the regime. The results sounded mixed, with many models ‘tripping up’ last year.
BNP’s Ben Steiner talked about ML’s model risk and echoed the idea that unlike physics, translation, tech, or engineering where ML is learning a ‘real’ phenomena like ‘recognizing a cat from an image’, ML in finance is often learning something that does not exist or is changing in the first place, bringing about a serious problem of model risk.
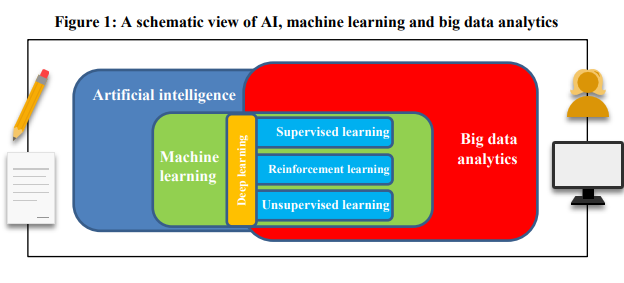
Source: Financial Stability Board, Two Centuries Investments
Now about Alternative Data
Alt Data is really a parallel development that has been accelerated by ML to some extent, but not all new data requires it.
The quickly growing list of alternative data providers (see a massive list here and here) feels rich with promise and creativity, yet many point to the ‘gold rush’ analogy - selling tools might be more profitable than looking for gold itself.
Data-sourcing is a new job function in many hedge funds, which is helping the new data vendors understand quant requirements, and refine their data for mass quant consumption.
What do I think?
Everyone wants to talk about AI, yet everyone thinks there is too much hype about AI. Some quants are saying that AI is nothing new, but just good old statistics with some extra computing power. Others are saying that the state of the art deep learning techniques are a real game changer and that traditional analytics can’t work with the large and complex datasets. Either way, we can find aspects of ML all over finance (see examples here).
I believe that the underlying fundamentals of incorporating latest technology and data remain the same. First, one needs great research questions, and then the tools to help find the answers. If the order is reversed and the tools are driving the ideas, then the ‘rabbit holes’ likely await. In the image above, I added the pencil and paper on the left, and a human and computer on the right to remind us of the important interaction between human thought and technology.
Just like the Compustat / IBES / Matlab of the 90’s, today’s Alt Data / ML will produce some exceptional results for those that have a unique innovation style and process.
Overall, I see great value in alternative data and targeted ML usage but only if it fits within your natural investment style.
“Most problems don’t require more data. They require more insight, more innovation and better eyes. Information is what we call it when a human being takes data and turns it into a useful truth.”
- Seth Godin, 3/24/2019
PS. I am currently carrying out my first academic style ML-101 experiment with a passionate ML expert at one of the top investment firms who believes that ML can forecast future prices based only on the past prices. We are doing a true ‘blind experiment’. I will be sending him anonymized time-series for only half of the full history. He will then develop the best ML forecasting model. I will then ask to store a copy of a time-stamped version of the code and then run it on the out-of-sample, second half of the history. My prediction is that it will look like the “inverted hockey stick”. Will I be surprised? Stay tuned for the results.
Cover image credit: Ling Languages, https://ling-app.com/